TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting
4SenseTime Research 5CUHK 6Nanyang Technological University
Introduction
We present a lightweight video motion retargeting approach that is capable of transferring motion in spite of structural and view-angle disparities between the source and the target.

Framework
Without using any paired data for supervision, the proposed method can be trained in an unsupervised manner by exploiting invariance properties of three orthogonal factors of variation including motion, structure, and view-angle. Specifically, with loss functions carefully derived based on invariance, we train an auto-encoder to disentangle the latent representations of such factors given the source and target video clips.
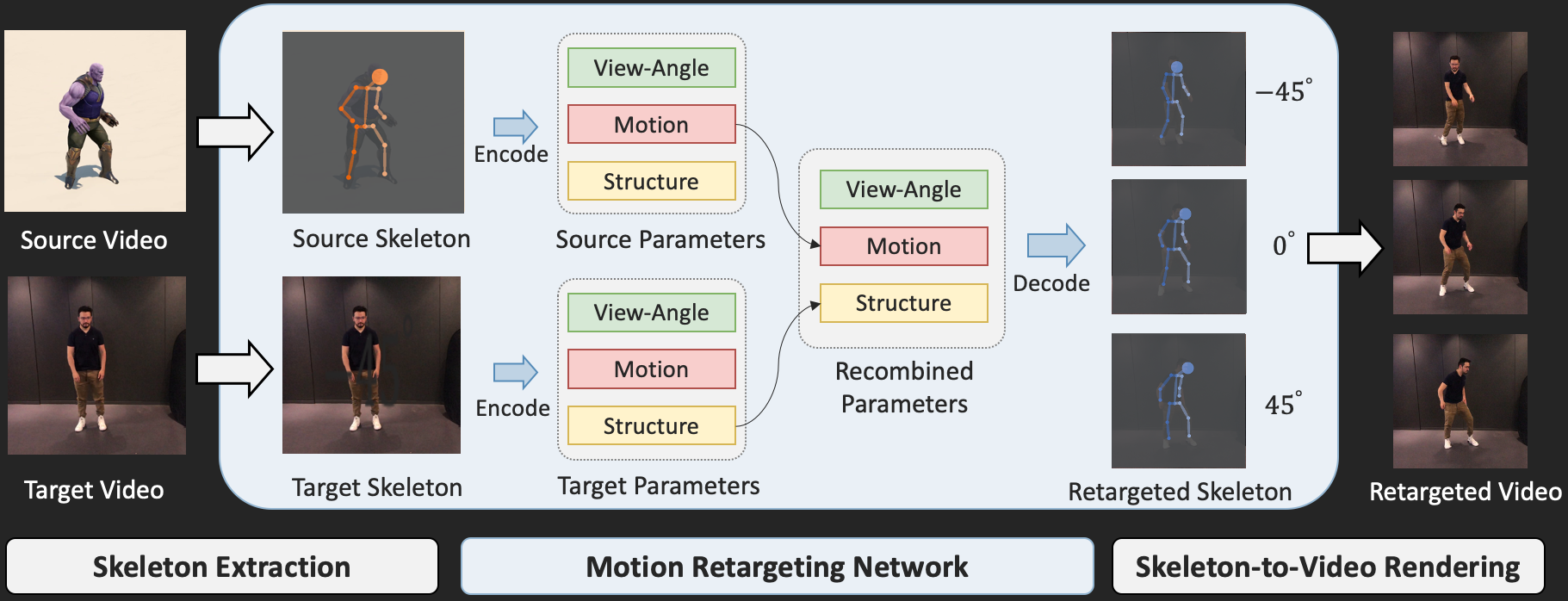
Unsupervised Representation Disentanglement
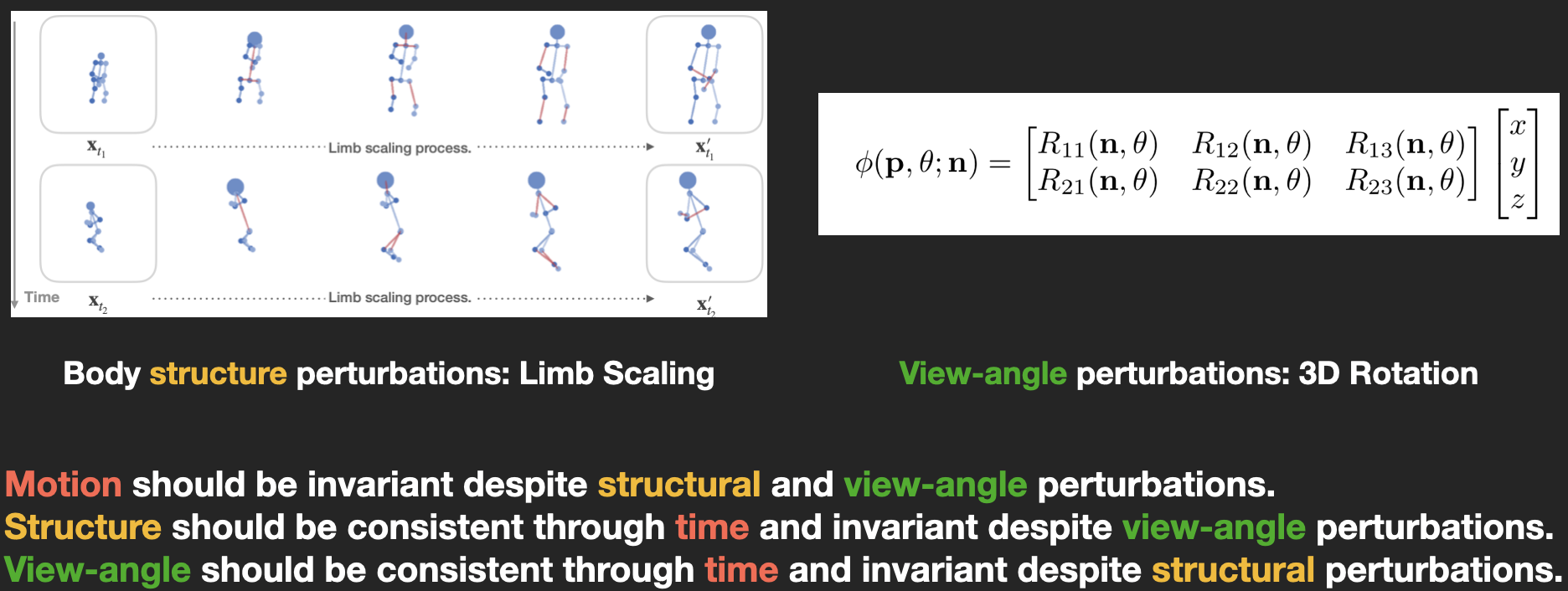
We exploit the invariance property of three factors: motion, structure, and view-angle. These factors of variation are enforced to be independent of each other, held constant when other factors vary. The invariance properties allow us to derive a set of purely unsupervised loss functions to train an auto-encoder for disentangling a sequence of skeletons into orthogonal latent representations.
Latent Motion Representation
The learned latent representation is meaningful when interpolated. In this video, body structure is interpolated on the horizontal axis while motion is interpolated on the vertical axis.
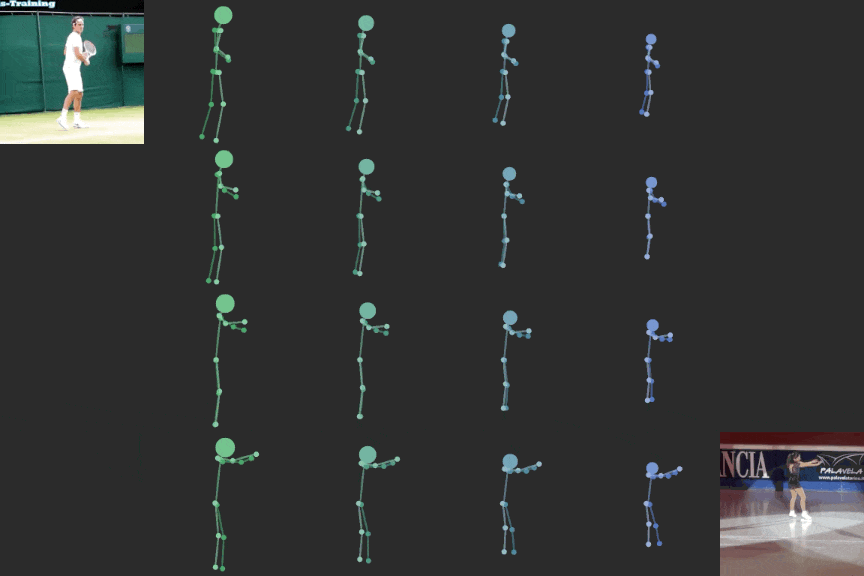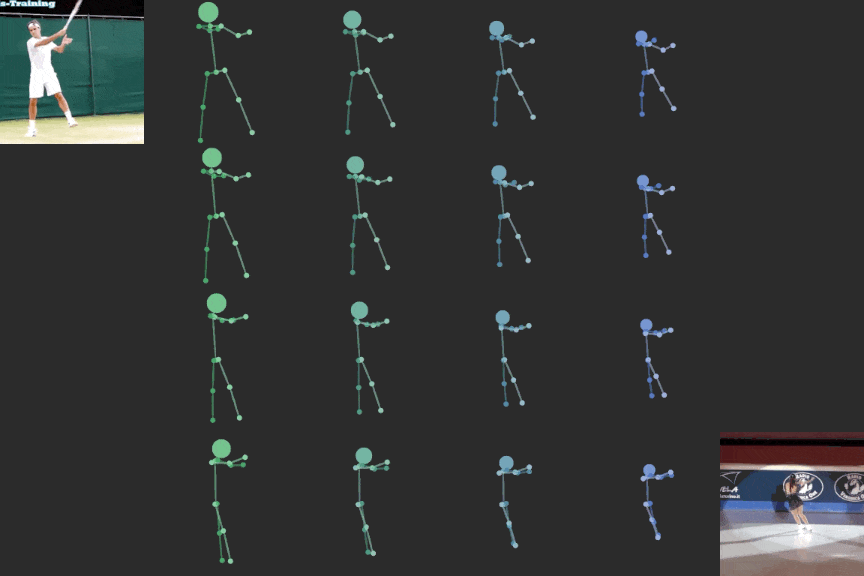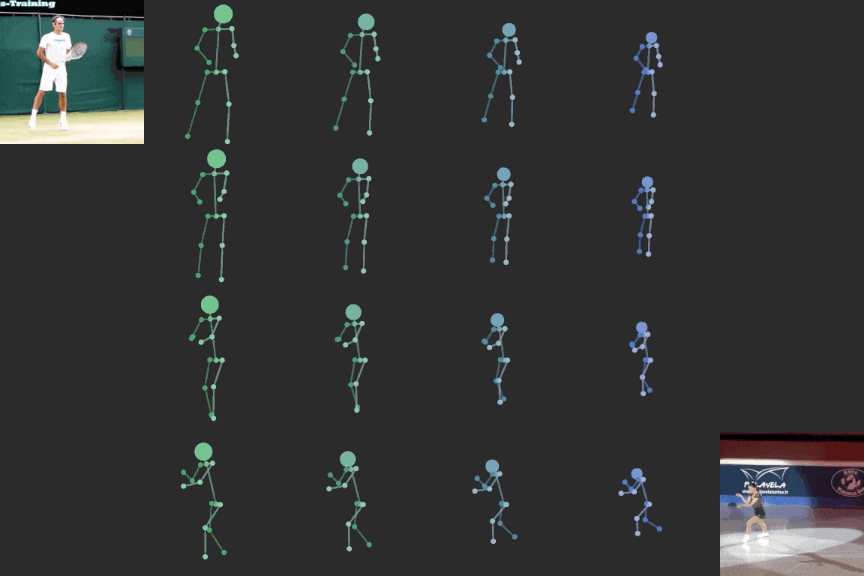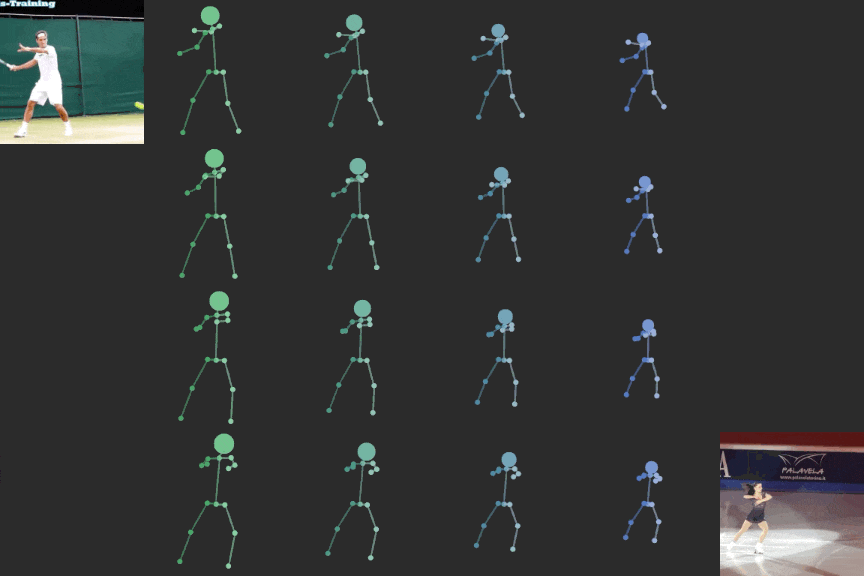
Novel View Synthesis
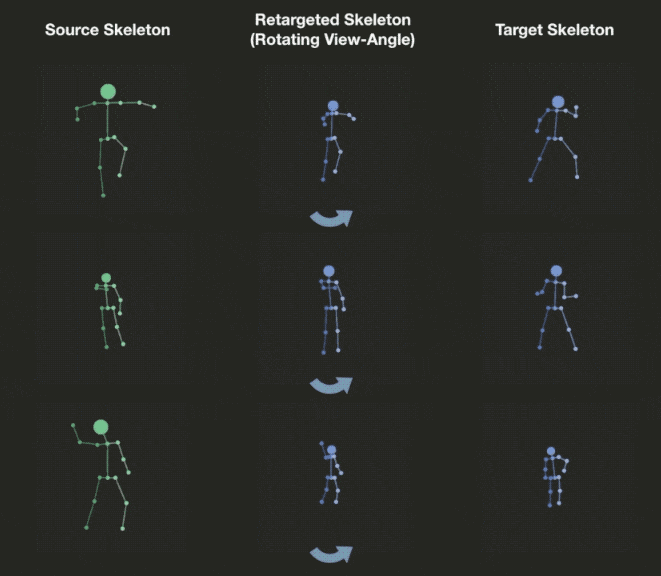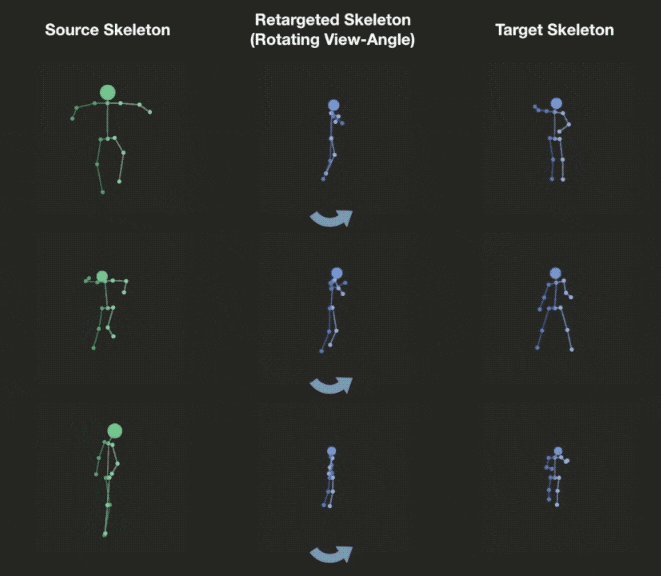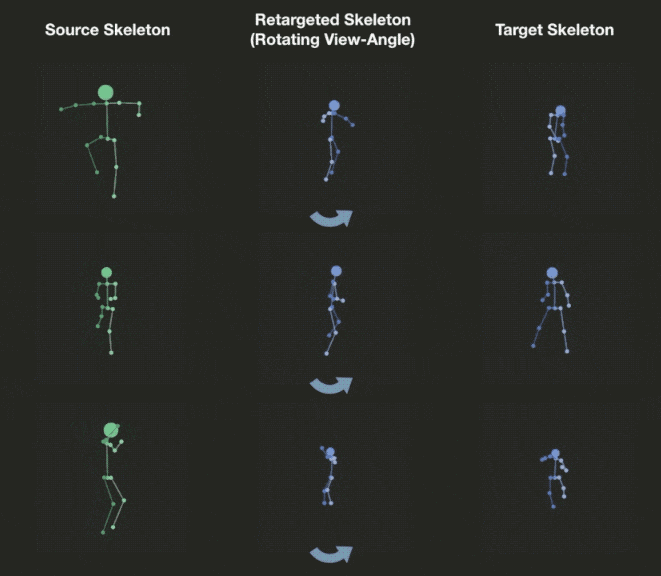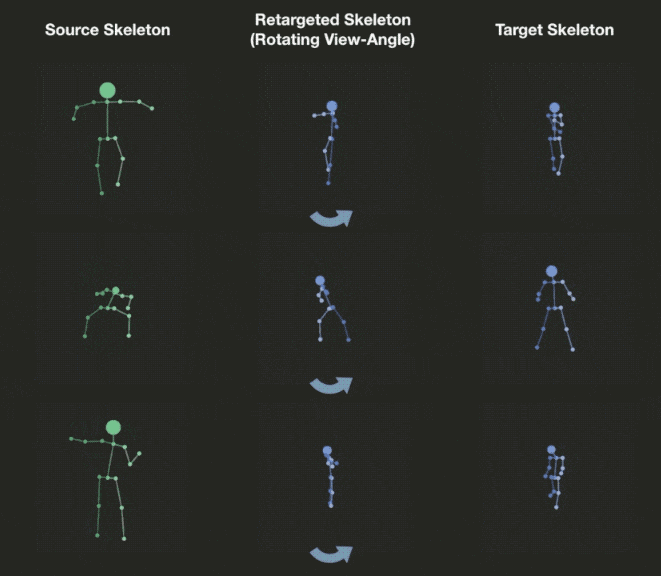
We can explicitly manipulate the view of decoded skeleton in the 3D space, rotating it before projecting down to 2D.
Video Demo
Citation
Z. Yang*, W. Zhu*, W. Wu*, C. Qian, Q. Zhou, B. Zhou, C. C. Loy. "TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting." IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020. (* indicates equal contribution.)
Bibtex:
@inproceedings{transmomo2020,
title={TransMoMo: Invariance-Driven Unsupervised Video Motion Retargeting},
author={Yang, Zhuoqian and Zhu, Wentao and Wu, Wayne and Qian, Chen and Zhou, Qiang and Zhou, Bolei and Loy, Chen Change},
booktitle={Computer Vision and Pattern Recognition},
year={2020}
}